Machbarkeitsnachweis: Generative Untertitel und Bildunterschriften


Videos und andere Medienformen sind immer häufiger der beste Weg, ein breites Publikum zu erreichen. Wer bewahrt schon noch Bedienungsanleitungen auf? Wenn ich das Dingsda an meinem Wie-heißt-es-noch-mal austauschen muss, gibt es dafür doch YouTube. Da sagt mir nicht nur jemand, wie man es macht, sondern zeigt es mir sogar!
Natürlich habe ich das Privileg, Muttersprachler zu sein, und mehr als die Hälfte aller Webinhalte ist auf Englisch. Die Welt liegt mir zu Füßen!
Aber was ist mit denen, die kein Englisch sprechen? Auch ihr Dingsda geht mal kaputt. Natürlich haben die meisten modernen Browser eine integrierte Funktion, um Text in anderen Sprachen anzuzeigen, aber leider keine Videos. Also doch wieder zurück zur Bedienungsanleitung!
Warum lokalisieren Autor:innen ihre Inhalte nicht? Das wäre doch gut für alle: diejenigen, die ein breites Publikum ansprechen und ihre persönlichen und professionellen Marken bewerben möchten, und diejenigen, die viel mehr Inhalte konsumieren würden, wenn sie für sie zugänglich wären. Die Antwort darauf ist ganz einfach: Videolokalisierung ist teuer.
Aber was macht sie so teuer?
- Es ist ein sehr komplexer Vorgang. So komplex, dass es spezielle Anwendungen gibt, wie die von unserem Partner CaptionHub, mit denen Profis diese Aufgabe erledigen können.
- Untertitel sind schwer zu übersetzen. Es gibt Beschränkungen für die Länge des Textes, der Text muss an das Video angepasst werden, Sätze werden aufgrund von Pausen abgeschnitten oder die Szene wechselt … die Liste ist noch länger. Es gibt gute Gründe, warum die Lokalisierung in der Regel von Expert:innen gehandhabt wird.
- Maschinelle Übersetzung kommt mit Segmentfragmenten nicht gut klar. Untertitel müssen aber zu dem passen, was im Video jeweils zu sehen ist, und dazu sind Fragmente erforderlich.
- Einfache Untertitel reichen nicht aus, damit Ihr Video für Hörgeschädigte zugänglich ist. Sie brauchen auch Bildunterschriften, damit Zuschauer:innen, die das Audio nicht hören können, dem Video trotzdem folgen können.
- Qualitätssicherung ist zeitaufwendig. Sie müssen sich das gesamte Video in allen Sprachen immer wieder ansehen, anhören und die Untertitel lesen … und noch mal … und noch mal …
- Jede Millisekunde muss stimmen. Denn die Zuschauer:innen merken sofort, ob der Untertitel der tatsächlichen Sprache entspricht.
Wo immer man hinsieht, wird KI gehypt. Sie kann Ihre Abschlussarbeit schreiben! Sie kann Ihr Auto fahren! Sie kann den Abwasch machen – nein, Moment, den muss ich noch selbst erledigen. Naja, kann sie denn zumindest meine Videos für alle zugänglich machen?
Die Antwort lautet: JA!
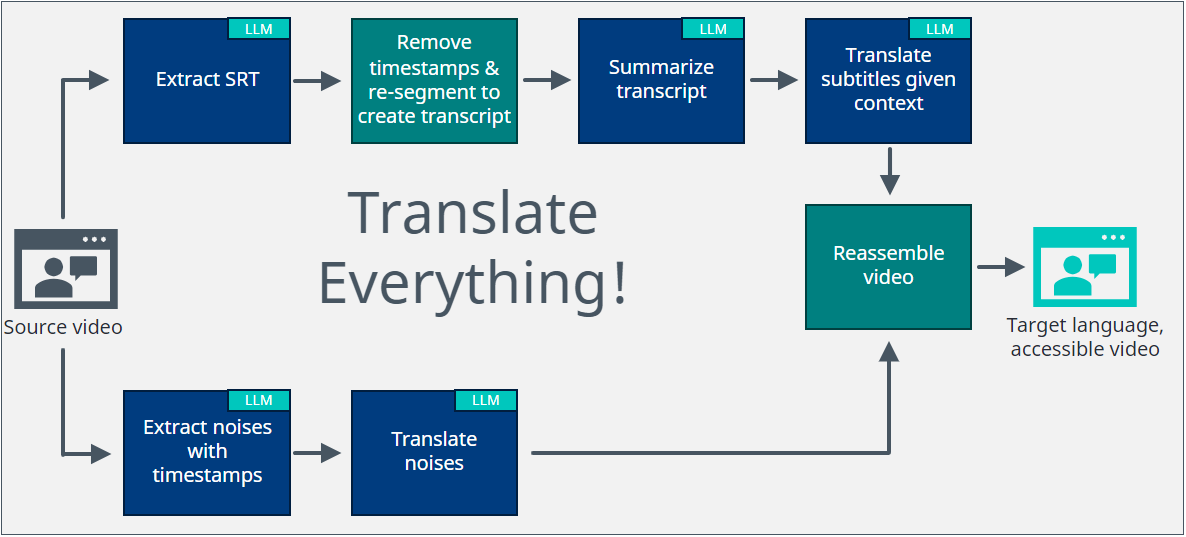
Wir können ein Video mithilfe von KI untertiteln. Es gibt allgemein verfügbare Large Language Models (LLMs), die das sehr gut machen. Aber Vorsicht – diese sind öffentlich, und Sie sollten gut überlegen, welche Inhalte Sie hochladen. In unserem Anwendungsfall? Es ist sehr hilfreich, wenn irgendjemand irgendwo weiß, wie man das Dingsda an dem Wie-heißt-es-noch-mal austauscht. Das sind keine vertraulichen Informationen. Alle sollen wissen, wer ich bin und wie das geht.
Sind diese LLMs und Untertitel perfekt? Wahrscheinlich nicht. Viele LLMs haben Probleme mit Markennamen und anderen Eigennamen. Ist das wichtig? Das hängt von der Situation ab. In meinen ausgefeilten Produktmarketingvideos oder in einem Video, das von der Personal- oder Rechtsabteilung verwendet werden könnte, kann ich mir keine Fehler leisten. Dafür werde ich weiterhin Fachleute einstellen. Aber für den Umgang mit meinem Dingsda? Da könnten die automatisierten Untertitel Ihre Erwartungen übertreffen.
Wunderbar, ich habe meine Untertitel. Und jetzt? Ich möchte keine der frei verfügbaren maschinellen Übersetzungen verwenden, weil sie nicht nur das Untertitelformat durcheinanderbringen, sondern auch für Segmentfragmente nicht gut geeignet sind. Die dramatische Pause in Ihrem Originalvideo? Sieht gut aus und klingt auch gut, aber jetzt habe ich statt eines ganzen Satzes zwei Halbsätze zu übersetzen.
Wie kann KI es besser machen? Als Erstes müssen Sie sichergehen, dass Ihr LLM weiß, worum es geht. Ein Absatz am Schuh ist nicht das gleiche wie der Absatz in einem Text. Ihrer öffentlichen maschinellen Übersetzung können Sie den Kontext nicht beibringen, aber Sie können Ihrem LLM sagen, worum es geht. Wir können also die Untertiteldatei nehmen und den Inhalt zusammenfassen.
Aber KI halluziniert auch manchmal! Das haben wir alle schon erlebt. Und ich möchte nicht, dass mein Dingsda auf magische Weise mit einem Wirbelzwirbel verbunden wird. Kein Problem. Nehmen wir also diese Zusammenfassung und sagen wir dem LLM, dass es diesen Kontext und nur diesen Kontext verwenden soll, um meine Untertitel zu übersetzen.
Wir dürfen aber auch die Barrierefreiheit nicht vergessen. Schließlich soll jede:r in der Lage sein, das Dingsda am Wie-heißt-es-noch-mal auszutauschen. Dieses Klicken, das man hört, wenn es richtig festgezogen ist? Sorgen wir dafür, dass auch hörgeschädigte Personen das Video verwenden können. LLMs können eingesetzt werden, um Geräusche mit Zeitstempeln zu extrahieren.
Vielleicht klingt das alles zu schön, um wahr zu sein, aber wenn Sie sehen möchten, wie wir es in einem realen Szenario unter Beweis gestellt haben, lade ich Sie ein, sich eine unserer aufgezeichneten Präsentationen von der diesjährigen ELEVATE anzusehen und aus den Sprachoptionen zu wählen, die für die Bildunterschriften verfügbar sind:

Queen hat es doch mal wieder am besten ausgedrückt: I want it all, and I want it now! Wenn Sie alles wollen, können Sie das haben – integriert und verfügbar, ohne dass Autor:innen es selbst zusammenschustern müssen. Hier kommen wir ins Spiel. Wir zeigen Ihnen, wie Sie am besten vorgehen, um die erstaunlichen neuen Möglichkeiten auszuschöpfen.
Alles erstellen … und einfach alles übersetzen, sogar Videos!
Shirley Coady
Alle von Shirley CoadyZugehörige Artikel
